Guardrails: The "Last Mile" of AI Safety
The Illusion of Safety in a Single Prompt
There is a widespread belief that safety in artificial intelligence is a matter of writing clever instructions. The thinking goes something like this: if we tell the AI to be helpful, harmless, and honest, it will obey. This is a dangerous oversimplification. A prompt is a suggestion. It is not a guarantee.
Consider how your organisation would approach physical security. You would not simply ask visitors to behave themselves and leave the doors unlocked. You would install barriers, verification systems, and monitoring. You would create layers of protection that do not depend on goodwill alone. The same principle applies to AI systems that interact with your customers, access your data, or represent your brand.
Safety is not a prompt. Safety is a system. The “last mile” of AI deployment, the moment when generated content reaches a real person, demands deterministic checks that operate independently of the language model itself. These checks are called guardrails, and they represent the difference between a prototype and a production system.
A guardrail agent is not a helper. It is a gatekeeper. Its sole purpose is to evaluate whether an AI output should pass or fail before it ever reaches a human being.
This distinction matters enormously. Most AI agents are designed to be useful, to answer questions, complete tasks, or generate content. A guardrail agent has a fundamentally different mandate. It exists to say no. It applies strict, predetermined criteria and makes a binary decision: this output is acceptable, or it is not.
Think of it as the quality control inspector at the end of a manufacturing line. The inspector does not build the product. The inspector does not improve the product. The inspector simply determines whether the product meets the standard. If it does, it ships. If it does not, it gets flagged, logged, and routed for review.
This gatekeeper approach provides something that prompt engineering alone cannot: determinism. When a guardrail agent checks for personally identifiable information, it either finds it or it does not. When it scans for prohibited content categories, the result is definitive. There is no ambiguity, no interpretation, no creative latitude.
The Performance Question: Speed vs Safety
The naive approach runs guardrails sequentially: generate output, check for harmful content, check for PII, check for compliance violations, then deliver. Each check waits for the previous one to complete. This works, but it is slow.
For most enterprise deployments, this parallel execution pattern reduces guardrail overhead from several hundred milliseconds to under one hundred. The safety remains identical; the speed improves dramatically.
No guardrail system is perfect. There will be moments when a legitimate request is blocked, when a valid customer query triggers a false positive. This is the inevitable trade off of any security system: the tighter the controls, the greater the chance of catching innocent traffic.
The response to this reality is not to loosen the guardrails. The response is to build feedback loops. Every blocked request should be logged with full context: what was the input, what was the output, which guardrail triggered, and what was the specific match. This data becomes the foundation for continuous improvement.
Over time, patterns emerge. Perhaps a particular product name keeps triggering your profanity filter. Perhaps certain industry terminology matches your PII detection rules. Each pattern is an opportunity to refine the system without compromising its core protective function. The goal is not zero false positives; that is impossible. The goal is a false positive rate low enough that the system remains trustworthy and the exceptions remain manageable.
When Good Requests Get Blocked
Mapping Guardrails to Compliance Frameworks
For regulated industries, guardrails are not optional enhancements. They are compliance requirements with legal force. The challenge is mapping specific guardrail implementations to specific regulatory obligations. For a deeper understanding of the jurisdictional issues driving these requirements, refer to our guide on Data Sovereignty in Regulated Environments.
Compliance Mapping Table:
Regulation
Core Requirement
Guardrail Implementation
GDPR Article 22
Right to Explanation
Log all AI decision factors; provide audit trail for automated decisions affecting individuals
GDPR Article 17
Right to Erasure
HIPAA Security
PII/PHI Protection
Deploy real-time PII masking; block outputs containing unredacted health information
HIPAA Audit
Access Logging
Maintain comprehensive logs of
all AI interactions involving
patient data
SOC2 CC6.1
Logical Access Controls
Implement role-based guardrail configurations; document access permissions
SOC2 CC7.2
System Monitoring
The table above represents a starting point rather than a complete solution. Each organisation must work with legal counsel to ensure their specific guardrail implementations satisfy their specific regulatory obligations. What matters is that the technical architecture supports compliance rather than working against it.
Circuit Breakers and Human Escalation
There are moments when an AI system should stop trying. When a user’s request has been blocked multiple times in succession, continuing to attempt AI resolution is not helpful. It is frustrating. This is where circuit breakers become essential.
Feature Grid - Three Components:

Threshold Detection
Monitor the pattern of blocks for each user session. When consecutive failures exceed the threshold, the system triggers escalation automatically.


Human Resolution
A real person reviews the flagged conversation with full context, resolves the issue, and the system learns from the outcome to reduce future escalations.
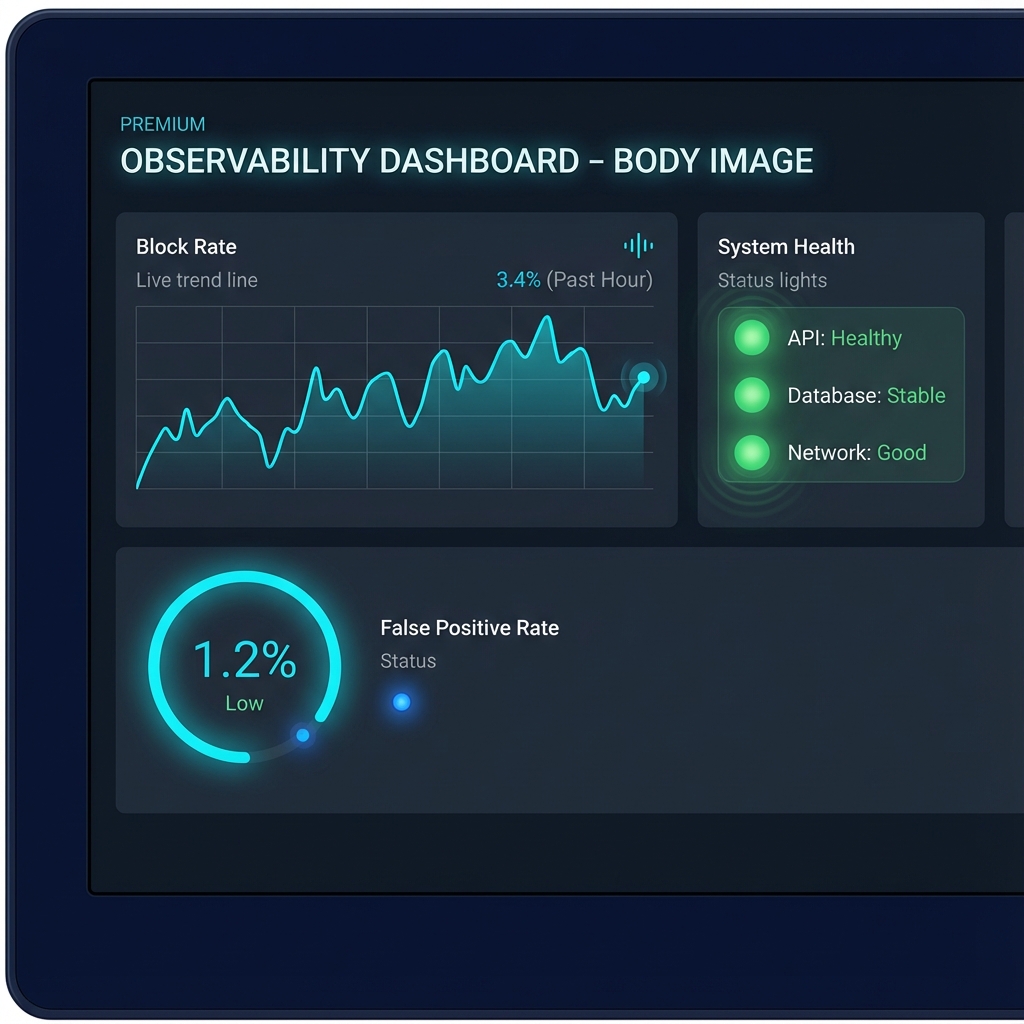
Watching the Watchers: Observability That Matters
Two metrics matter above all others: Block Rate and False Positive Rate.
Block Rate tells you how often your guardrails are triggering. A rate that is too low suggests your guardrails may be too permissive. A rate that is too high suggests they may be too restrictive, or that your AI is producing problematic outputs at an alarming frequency. Either extreme warrants investigation.
False Positive Rate tells you how often your guardrails are wrong. This requires manual review of a sample of blocked outputs to determine what percentage were incorrectly flagged. Industry benchmarks vary, but a False Positive Rate under five percent is generally considered acceptable for production systems.
These metrics should be visible in real time on a dedicated dashboard. They should trigger alerts when thresholds are exceeded. They should be reviewed regularly by both technical and business stakeholders. The guardrails protect your users. The observability protects your guardrails.

Ready to Implement Multi-Agent AI?
Book a consultation to explore how the Council of Experts framework can transform your AI capabilities.
Discover more AI Insights and Blogs
By 2027, your biggest buyer might be an AI. How to restructure your Ecommerce APIs and product data so "Buyer Agents" can negotiate and purchase from your store automatically
Dashboards only show you what happened. We build Agentic Supply Chains that autonomously reorder stock based on predictive local trends, weather patterns, and social sentiment
Stop building static pages. Learn how we configure WordPress as a "Headless" receiver for AI agents that dynamically rewrite content and restructure layouts for every unique visitor
One agent writes, one edits, one SEO-optimizes, and one publishes. How we build autonomous content teams inside WordPress that scale your marketing without scaling your headcount
One model doesn't fit all. We break down our strategy for routing tasks between heavy reasoners (like GPT-4) and fast, local SLMs to cut business IT costs by 60%
Don't rewrite your old code. How we use Multi-Modal agents to "watch" and operate your legacy desktop apps, creating modern automations without touching the source code
You wouldn't give an intern root access to your database. Why are you giving it to ChatGPT? Our framework for "Role-Based Access Control" in Agentic Systems