The Context Window Trap
Trap Why Infinite Context Won't Solve Your Retrieval Problems
The Allure of Infinite Context
When OpenAI announced GPT-4 Turbo with a 128k context window, and Google followed with Gemini’s 1 million token capacity, the message seemed clear: the future belongs to models that can process entire libraries in a single prompt. Why bother with complex retrieval systems when you can simply dump everything into the context and let the model figure it out?
It’s an appealing proposition. No chunking strategies. No embedding models. No vector databases. Just raw, brute-force comprehension at scale. For businesses drowning in documentation, the promise of “upload everything, ask anything” feels like liberation.
But there’s a problem. Behind the impressive token counts lies a set of technical, economic, and practical limitations that make massive context windows far less magical than the marketing suggests. In our testing at CLOUDTECH, we’ve found that retrieval-augmented generation (RAG) consistently outperforms context stuffing for real-world enterprise use cases.
The “Lost in the Middle” Phenomenon
Here’s a technical reality that rarely appears in product announcements: large language models don’t process context uniformly. Research from Stanford and UC Berkeley has demonstrated what practitioners call the “lost in the middle” effect. When models receive long context inputs, they exhibit a distinctive U-shaped attention pattern. Information at the beginning and end of the context receives strong attention, while content in the middle effectively disappears into a cognitive blind spot.
Think of it like reading a 500-page report in one sitting. You remember the introduction clearly. The conclusion sticks with you. But ask about chapter 14? Your recall becomes fuzzy at best.
In practical terms, this means that dumping 100 documents into a million-token context window doesn’t give you access to all 100 documents. You get reliable access to perhaps the first few and the last few. Everything in between becomes probabilistic. The model might retrieve it accurately. It might hallucinate. It might simply ignore crucial information that happens to fall in the forgotten middle.
Statistic
40%
Accuracy Variance
Our internal testing confirmed this pattern. When we placed critical information at various positions within a 200k token context, retrieval accuracy varied by as much as 40% depending on position alone. The same question, the same information, wildly different results based purely on where the data happened to sit in the context window.
The Economics of Context: Needle in a Haystack Pricing
- Token Stock
900
RAG Token Per Query
- Token Stock
800,300
Total billable tokens
- Multiplier
890x
cost multiplier
Let’s talk money. API pricing for large language models follows a simple formula: you pay per token processed. This applies to both input (your context) and output (the model’s response). When you stuff a million tokens into every query, you’re paying for a million tokens of processing whether you need that information or not.
Consider a typical enterprise scenario. A customer support agent needs to answer a question about warranty terms for a specific product. The relevant information exists in a two-paragraph section of a product manual: approximately 400 tokens. Under a RAG approach, you retrieve those 400 tokens, add them to a 200-token query, and receive a 300-token response. Total billable tokens: roughly 900.
Now consider the context-stuffing approach. You load all product manuals (let’s say 500,000 tokens), all policy documents (200,000 tokens), and all FAQ content (100,000 tokens) into the context window. Same query, same 300-token response. Total billable tokens: 800,300.
That’s an 890x cost multiplier for identical output quality. At current API rates, a query that costs £0.002 with RAG becomes £1.78 with context stuffing. Scale that across thousands of daily queries, and you’re looking at the difference between a £60 monthly bill and a £53,000 monthly bill.
The mathematics become even more punishing when you factor in the “lost in the middle” problem. You’re not just paying 890 times more. You’re paying 890 times more for worse accuracy.
Latency: The User Experience Factor
Cost isn’t the only variable that scales with context size. Processing time does too. When a model must attend to a million tokens before generating a response, that attention mechanism requires computational cycles. Many of them.
In our benchmarks, we measured time-to-first-token (TTFT) across various context sizes using identical queries. The results were striking. With a 4,000-token context (typical for well-designed RAG), TTFT averaged 0.8 seconds. At 128,000 tokens, TTFT climbed to 4.2 seconds. At 500,000 tokens, we recorded an average of 11.6 seconds before the first word appeared.
For a chatbot answering customer questions, 11 seconds of dead air feels like an eternity. Users begin to wonder if the system has crashed. They refresh pages, abandon sessions, reach for the phone to call a human instead.
There’s also the question of throughput. A model spending 11 seconds per query can handle roughly 327 queries per hour. The same model responding in 0.8 seconds can handle 4,500 queries per hour. That’s a 14x difference in capacity from the same infrastructure.
Our Testing: What the Data Shows
We didn’t want to rely on theoretical arguments alone. Over the past quarter, our AI team conducted structured testing across multiple context-length scenarios using a standardised question set against a 2.3 million token document corpus.
The testing methodology was straightforward. We embedded 50 specific factual questions with verifiable answers throughout the corpus. We then ran identical question sets against the same base model using three approaches: RAG with a 4,000-token retrieval window, full context loading at 200,000 tokens, and full context loading at 800,000 tokens.
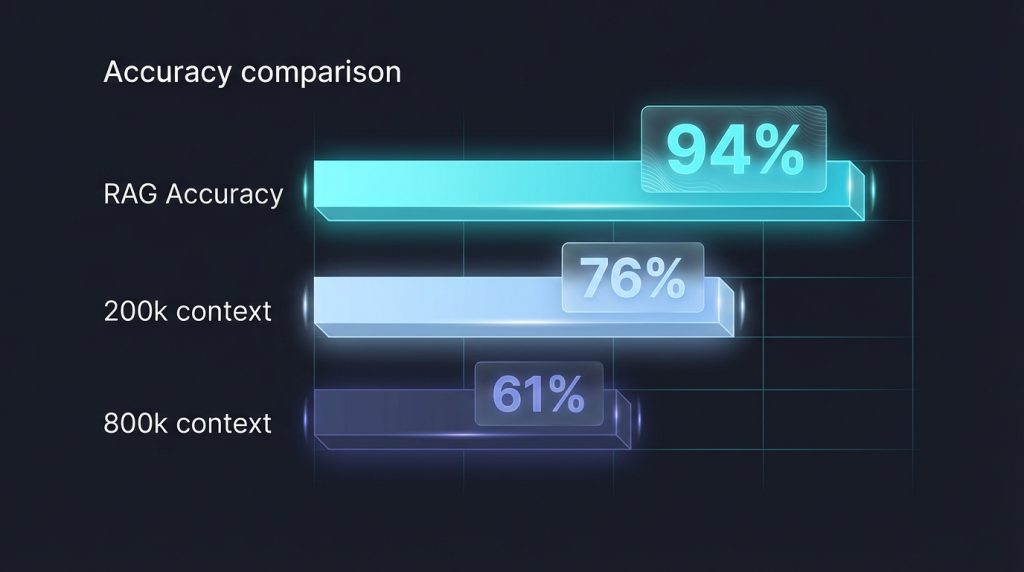
Accuracy results told a clear story. RAG retrieval achieved 94% accuracy across all questions. The 200k context window scored 76%. The 800k context window dropped to 61%. Critically, the accuracy decline wasn’t random. It followed the predicted “lost in the middle” pattern, with questions targeting the centre of the context showing the steepest accuracy drops.
Perhaps more revealing was the consistency metric. RAG produced consistent answers across repeated runs in 98% of cases. The large context approaches showed answer variance in 23% to 34% of repeated identical queries. For enterprise applications where reliability matters, this inconsistency represents a serious operational risk.

We also measured “confident hallucination” rates: instances where the model provided incorrect information with high apparent certainty. RAG hallucination rate: 3%. Context-stuffing hallucination rate: 12 to 18%. The larger the context, the more willing the model seemed to confabulate.
The RAG Alternative: Precision Over Volume
Precise Retrieval
Retrieval-augmented generation isn’t new, and it isn’t glamorous. It requires thoughtful architecture: document chunking strategies, embedding model selection, vector database configuration, and retrieval ranking logic. It’s more work than simply increasing a context window parameter.
Cost Efficient
But that work pays dividends. A well-designed RAG system retrieves only what’s needed, when it’s needed. It places critical information at the top of a focused context where attention is strongest. It scales economically because you’re paying for relevance rather than volume. It responds quickly because there’s less to process.
Auditability
RAG also provides something that context stuffing cannot: explainability. When a RAG system answers a question, you can trace exactly which document chunks contributed to that answer. You can audit, debug, and improve. With context stuffing, the model’s attention patterns remain opaque. You know what went in. You know what came out. The middle is a black box.
For organisations building production AI systems, this transparency matters. When the answer is wrong, you need to know why. When regulations require audit trails, you need documentation. RAG provides these capabilities by design.
Building for Reality, Not Headlines
The race to larger context windows makes for impressive benchmarks and compelling press releases. For most real-world applications, however, the fundamentals haven’t changed. Focused retrieval outperforms brute-force inclusion. Precision beats volume. Economics still matter.
None of this means large context windows have no value. They excel at certain tasks: analysing lengthy single documents, maintaining extended conversation history, processing codebases that resist chunking. The technology has genuine applications.
But as a default strategy for enterprise knowledge management? As a replacement for thoughtful retrieval architecture? The data simply doesn’t support it. Models get lost in the middle. Costs multiply. Latency suffers. Reliability degrades.
At CLOUDTECH, we help organisations build AI systems that work in production, not just in demos. That means honest conversations about trade-offs, architecture decisions based on evidence, and solutions designed for operational reality. If you’re evaluating approaches to enterprise AI retrieval, we’d welcome the opportunity to share what we’ve learned.

Ready to Implement Multi-Agent AI?
Book a consultation to explore how the Council of Experts framework can transform your AI capabilities.
Discover more AI Insights and Blogs
By 2027, your biggest buyer might be an AI. How to restructure your Ecommerce APIs and product data so "Buyer Agents" can negotiate and purchase from your store automatically
Dashboards only show you what happened. We build Agentic Supply Chains that autonomously reorder stock based on predictive local trends, weather patterns, and social sentiment
Stop building static pages. Learn how we configure WordPress as a "Headless" receiver for AI agents that dynamically rewrite content and restructure layouts for every unique visitor
One agent writes, one edits, one SEO-optimizes, and one publishes. How we build autonomous content teams inside WordPress that scale your marketing without scaling your headcount
One model doesn't fit all. We break down our strategy for routing tasks between heavy reasoners (like GPT-4) and fast, local SLMs to cut business IT costs by 60%
Don't rewrite your old code. How we use Multi-Modal agents to "watch" and operate your legacy desktop apps, creating modern automations without touching the source code
You wouldn't give an intern root access to your database. Why are you giving it to ChatGPT? Our framework for "Role-Based Access Control" in Agentic Systems